企业敏感数据保护首要问题是实时掌握敏感数据分布与变化,并做好分类分级及其他管控措施的联动。
《数据安全法》和《个人信息保护法》等法律法规以及相应的数据安全监管要求,催生了企业对重要数据、个人敏感信息的保护需求,而敏感数据的发现与分类分级是数据保护工作的首要步骤。然而,在企业的数据保护工作中,确存在一些现实困难。
敏感数据是指泄漏后可能会给社会或个人带来严重危害的数据。包括个人隐私数据,如姓名、身份证号码、住址、电话、银行账号、邮箱、密码、医疗信息、教育背景等;也包括企业或社会机构不适合公布的数据,如企业的经营情况,企业的网络结构、IP地址列表等。
企业数字化转型的全速推进,多云、混合云成为企业 IT 基础设施的主要形态,传统企业数据中心到多种公有云、行业云、私有云同时存在,企业数据安全运维管理面临着极大的挑战。特别是基于云原生技术的数字化应用,数据管理工具集可能会有所不同,这会增加运营成本。
与此同时,中小企业在开发运维方面的人力始终处于不饱和状态,而大型企业因为业务条线的区隔存在资源与管理规范的差异难以统一。不规范的运维备份、未及时销毁的过期数据,给后期敏感数据管理带来难点。
敏感数据资产梳理如果完全依靠手工作业,效率非常低下。企业即使使用敏感数据资产扫描这类工具,也存在更新效率与实时性的问题。
在做敏感数据梳理过程中,数据安全管理人员需要运维部门或应用开发部门的配合与授权;传统的工具依赖主动扫描,为保障业务的正常进展或受限于庞大的数据量,无法做进行高频扫描,也就无法实时感知到敏感数据变化。尤其是出现新的数据库、表、字段、数据内容时,发现、保护等都会出现延迟,必然会发生敏感数据发现遗漏、偏离等问题。
基于业务特点与法规要求的分类分级可以更好地将数据资产化,持续性为企业提供精准的数据服务;同时数据分级可以在安全角度为企业保驾护航,哪些数据可以使用、哪些不可以使用、哪些能对外开放、哪些不能开放、不同等级的数据在后续的工作中配置哪种安全策略,一目了然。
因此,敏感数据的发现要与分类分级联动,同时分类分级也要与与后续的保护技术措施联动,独立的分类分级工程可能无法达成投资效益。
原点 CDPP 产品是基于 Kubernetes/Docker 技术开发的数据安全产品,能够很好地适应云基础设施,易于和云原生业务应用集成,部署各种数据访问工具/业务应用与数据源之间, 保护分布在多云、混合云场景中的敏感数据。
敏感数据资产目录 SDI(Sensitive Data Inventory)是 CDPP 产品的重要组成部分,通过自动化的数据访问流量解析技术、敏感数据智能识别技术、数据分类分级自动化标注技术,帮助企业建立起敏感数据的资产目录,并支持自定义敏感数据类型和手工标注,大大增强了企业敏感数据的可见度。
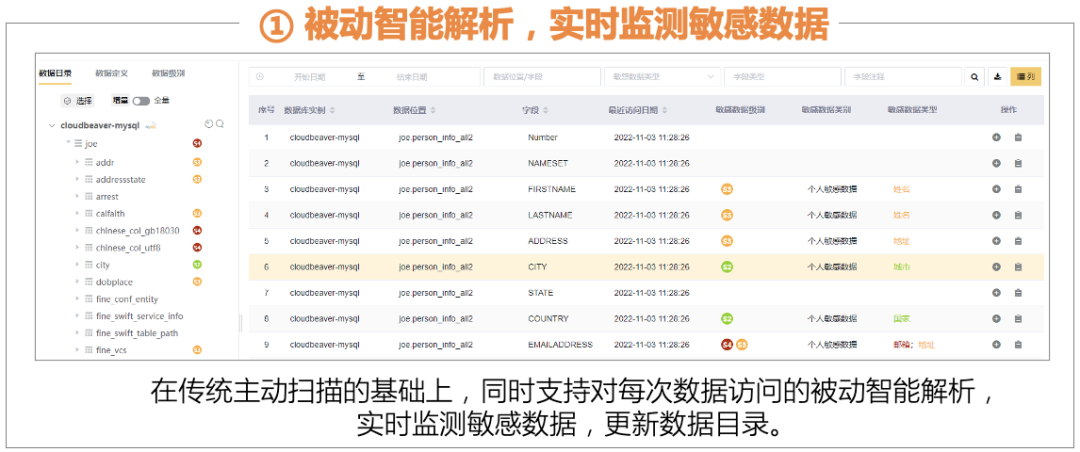
1、主动+被动,实时监测敏感数据
支持两种模式的敏感数据资产发现
● 主动模式
通过主动扫描数据库采样的方式,发现敏感数据。支持自定义敏感数据发现任务,主动针对数据源进行数据采样并识别敏感数据,需配置数据源系统的账号和口令。内置四大类 50 多种个人敏感数据类型,支持自定义敏感数据类型和发现规则。
● 被动模式
可以在用户通过应用程序正常使用数据的过程中,自动学习和识别敏感数据。在被动工作模式下,无需获取数据库系统的账号口令即可完成敏感数据的发现,当应用升级导致数据库 schema 发生变化时,SDI 也能够及时自动更新资产目录,保证敏感数据资产目录的新鲜度。
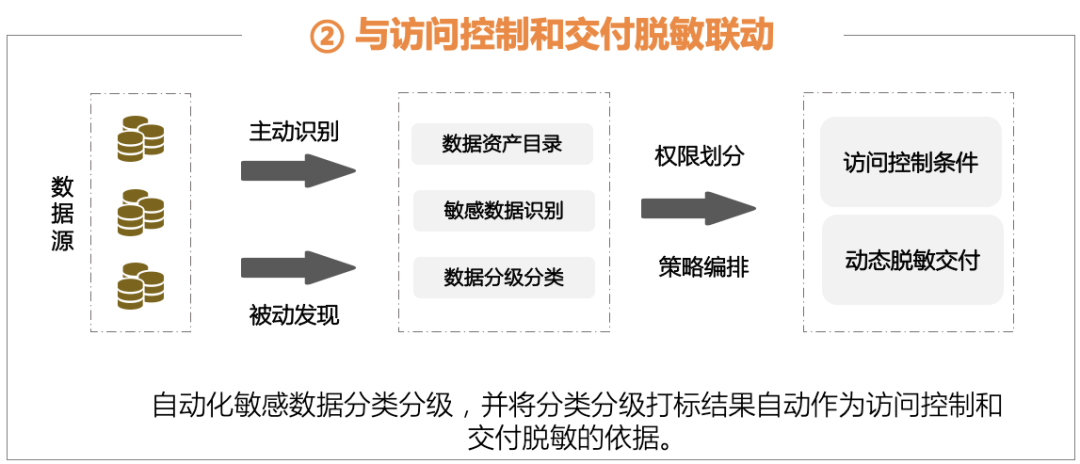
2、与访问控制和交付脱敏联动
● 自动标注分类分级:
基于发现的敏感数据,可以自动进行分类分级标注,帮助企业从安全角度梳理敏感数据资产,支持自定义标签,支持数据类型的手工标注。
● 联动管控措施:
针对自定义的数据集以及用户/用户组、敏感数据类型、安全级别、用户标签配置访问控制策略。并根据自身的应用场景配置脱敏算法和脱敏规则组合,实现应用前端展示的敏感数据动态脱敏,无需修改应用程序代码。
敏感数据的实时发现,让数据保护更实时更高效。数据分类分级,与保护技术措施联动,体系化数据保护从此开始。
上一篇:盘点个人信息保护方面的那些认证









